Research
My research falls into
systems' management and dependable systems
\begin{itemize}
\parsep=0in
\parskip=0in
\itemsep=0in
\item Distributed systems management and autonomic computing
\item Adaptive monitoring, error detection and fault diagnosis
\item Behavioural modeling of systems software
\item Cloud monitoring?
two major areas: computer networks and distributed systems.
Distributed systems starts from the perspective of a collection
of (possibly semi-) connected computers and then asks the
question: how do we use them, how do we make them easy to use,
and how do we make them dependable? My research in each of
these areas is described in a little more detail below.
|

|
Distributed-systems research, at its heart, is about finding the right
abstractions and mechanisms for designing and developing systems that
execute dependably over collections of networked computers. This is a
lot harder than it sounds, because distributed systems are different
from centralized computers in a number of fundamental ways: partial
failure may (will!) occur, events are not totally ordered, there are
no common resources (clock, storage, etc.), latency to access
items varies dramatically. These differences are
fundamental. That is to say, you cannot mask them. You can
pretend that they are not there, but this will fail some percentage of
the time, and likely perform poorly much of the time.
Given that these differences exist, what are the correct models with
which to create distributed systems. Historically there are two major
approaches: process groups and client/server computing. Examples of
the first of these include peer-to-peer (P2P) systems, grid computing
(possibly), virtual synchrony, publish/subscribe systems, etc..
Examples of client/server abstractions include the Distributed
Computing Environment (DCE), the Common Object Request Broker
Architecture (CORBA), Service-Oriented Architectures (SOA, including
Web Services), etc.. The dominant abstraction used in large
enterprise systems is client/server computing.
Within these frameworks, there are then many open research problems.
My research focus has been primarily on distributed-system debugging and
management, which is to say, how do you know that your code is
correct and how do you know that your application is functioning
correctly. More recently that has morphed into self-managing systems. I also pursue
research in SOA and some work on P2P systems. These are described below.
Distributed-System Management
Distributed-system management is defined as the dynamic observation of
a distributed computation and the use of information gained by that
observation to dynamically control the computation.
Distributed-system observation consists of collecting runtime data
from executing computations and then presenting that data in a
queryable form for computation-control purposes. The purpose of the
control is varied and includes debugging, testing, computation
visualization, computation steering, program understanding, fault
management, system management, and dependable distributed computing.
Tools for distributed-system management, such as POET, Object-Level
Trace, and the MAD environment, can be broadly described as having the
architecture shown below.
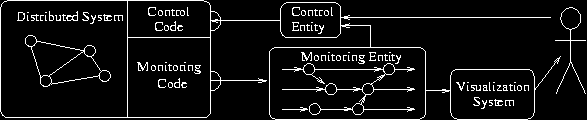
The distributed system is the system under observation. A distributed
system is a system composed of loosely coupled machines that do not
share system resources but rather are connected via some form
of communication network. The communication channels are, relative to
the processing capacity, low bandwidth and high latency. Note that
while network bandwidths are improving, latency remains high.
Further, because of Moore's law,it is not clear that network
bandwidths are improving relative to processor performance. Likewise,
it is clear that wide-area latency will only get worse relative to
processor performance because of the laws of physics.
Both the machines and the network may be faulty in various ways. The
failure of any machine or portion of the network in any particular way
does not imply the failure of the whole system. Indeed, partial
failure is one of the most difficult aspects to deal with in
distributed systems.
The distributed system is instrumented with monitoring code that
captures significant event data. The information collected will
include the event's process identifier, number, and type, as well as
partner-event identification, if any. This event data is forwarded
from each process to a central monitoring entity which, using this
information, incrementally builds and maintains a data structure of
the partial order of events that form the computation. That data
structure may be queried by a variety of systems, the most common
being visualization engines for debugging and control entities.
Most of my research in this area has focused on the scalability of the
data collection. In particular, given the large number of events, my
dissertation looked at the problem of creating a scalable data
structure for storing and querying these events. This work has
focused on the need for efficient space-complexity. More recently, I
have studied problems pertaining to pattern seeking within these
event sets, as well as correlating events.
Self-Managed Systems
On of the potential uses of distributed-system management is to have
the system self-manage. Indeed, in 2001 IBM recognized the need for
self-managing systems, and started an initiative they termed Autonomic
Computing. Their model for an autonomic element is shown below.
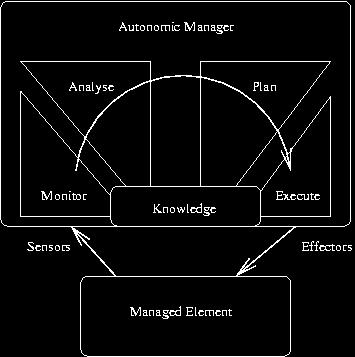
A moment's thought shows how similar this is to the distributed-system
management tool architecture above, and I have written a brief paper to this effect. There
is, however, something of a critical difference. In IBM's world,
systems cannot simply be instrumented as needed by the demands of a
self-managing system. There is too much legacy code that has to be
managed. However, there is the ability to tap into the monitoring
that such systems do already provide (e.g., in the the form of
log records) as well as monitoring the environment. As such, we
proceed from a "what can we do given the data we are given" view,
rather than, as is typical in systems management "gather what data we
need."
Collecting and integrating this data has been an initial focus of my
research in this area. We are now correlating this data to do fault
diagnosis, with the intent on automated system repair.